
MEDIDAS
DE VARIABILIDAD O DISPERSIÓN
Los estadísticos de tendencia central o posición
nos indican donde se sitúa un grupo de puntuaciones. Los de variabilidad
o dispersión nos indican si esas puntuaciones o valores están próximas
entre sí o si por el contrario están o muy dispersas.
Una medida razonable de la variabilidad podría ser la amplitud
o rango, que se obtiene restando el valor más bajo de un conjunto de observaciones
del valor más alto. Es fácil de calcular y sus unidades son las mismas que las
de la variable, aunque posee varios inconvenientes:
![]() No utiliza todas las observaciones
(sólo dos de ellas);
No utiliza todas las observaciones
(sólo dos de ellas);
![]() Se puede ver muy afectada por alguna
observación extrema;
Se puede ver muy afectada por alguna
observación extrema;
![]() El rango aumenta con el número de
observaciones, o bien se queda igual. En cualquier caso nunca disminuye.
El rango aumenta con el número de
observaciones, o bien se queda igual. En cualquier caso nunca disminuye.
En el transcurso de esta sección, veremos medidas de
dispersión mejores que la anterior. Estas se determinan en función de la distancia
entre las observaciones y algún estadístico de tendencia central.
Desviación media, Dm
Se
define la desviación media como la media de las diferencias en valor
absoluto de los valores de la variable a la media, es decir, si tenemos un
conjunto de n observaciones, x1, ...,
xn, entonces
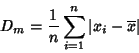
Si los datos están agrupados en una tabla estadística es más
sencillo usar la relación
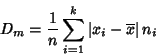
Como se observa, la desviación media guarda las mismas dimensiones que las
observaciones. La suma de valores absolutos es relativamente sencilla de calcular,
pero esta simplicidad tiene un inconveniente, esto hace que sea muy engorroso
trabajar con ella a la hora de hacer inferencia a la población.
Varianza y desviación típica
Como
forma de medir la dispersión de los datos hemos descartado:
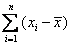 , pues sabemos que esa suma vale 0, ya que las
desviaciones con respecto a la media se compensan al haber términos en esa
suma que son de signos distintos.
, pues sabemos que esa suma vale 0, ya que las
desviaciones con respecto a la media se compensan al haber términos en esa
suma que son de signos distintos. - Para tener el mismo signo al
sumar las desviaciones con respecto a la media podemos realizar la suma
con valores absolutos. Esto nos lleva a la Dm, pero como hemos mencionado,
tiene poco interés por las dificultades que presenta.
Si
las desviaciones con respecto a la media las consideramos al cuadrado, ![]() , de nuevo obtenemos que todos los sumandos tienen el
mismo signo (positivo). Esta es además la forma de medir la dispersión de los
datos de forma que sus propiedades matemáticas son más fáciles de utilizar.
, de nuevo obtenemos que todos los sumandos tienen el
mismo signo (positivo). Esta es además la forma de medir la dispersión de los
datos de forma que sus propiedades matemáticas son más fáciles de utilizar.
Vamos
a definir entonces dos estadísticos que serán fundamentales en el resto
del curso: La varianza y la desviación típica.
La varianza, ![]() , se define como la media de
las diferencias cuadráticas de n puntuaciones con respecto a su media
aritmética, es decir
, se define como la media de
las diferencias cuadráticas de n puntuaciones con respecto a su media
aritmética, es decir
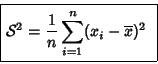
Para
datos agrupados en tablas, usando las notaciones establcidas
en los capítulos anteriores, la varianza se puede escibir
como
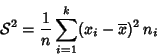
Una
fórmula equivalente para el cálculo de la varianza es
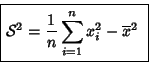
Si
los datos están agrupados en tablas, es evidente que
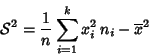
La
varianza no tiene la misma magnitud que las observaciones (ej.
si las observaciones se miden en metros, la varianza lo hace en ![]() ). Si queremos que la medida de
dispersión sea de la misma dimensionalidad que las observaciones bastará con tomar su raíz cuadrada. Por ello se define la desviación
típica,
). Si queremos que la medida de
dispersión sea de la misma dimensionalidad que las observaciones bastará con tomar su raíz cuadrada. Por ello se define la desviación
típica, ![]() , como
, como
![]()
Ejemplo
Calcular la varianza y desviación típica de las siguientes
cantidades medidas en metros:
3,3,4,4,5
Solución: Para calcular dichas medidas de
dispersión es necesario calcular previamente el valor con respecto al cual
vamos a medir las diferencias. Éste es la media:
![]()
La
varianza es:
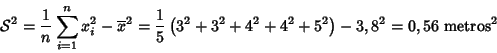
siendo la desviación típica su raíz cuadrada:
![]()
Observación
Además de las propiedades que hemos demostrado sobre la
varianza (y por tanto sobre la desviación típica), será conveniente tener
siempre en mente otras que enunciamos a continuación:
- Ambas son sensibles a la
variación de cada una de las puntuaciones, es decir, si una puntuación
cambia, cambia con ella la varianza. La razón es que si miramos su
definición, la varianza es función de cada una de las puntuaciones.
- Si se calculan a traves de los datos agrupados en una tabla, dependen
de los intervalos elegidos. Es decir, cometemos cierto error en el cálculo
de la varianza cuando los datos han sido resumidos en una tabla
estadística mediante intervalos, en lugar de haber sido calculados
directamente como datos no agrupados. Este error no será importante si la
elección del número de intervalos, amplitud y límites de los mismos ha
sido adecuada.
- La desviación típica tiene la
propiedad de que en el intervalo
![]()
se encuentra, al menos, el 75% de las
observaciones (vease más adelante el teorema de Thebycheff, página ![]() ). Incluso si
tenemos muchos datos y estos provienen de una distribución normal (se
definirá este concepto más adelante), podremos llegar al 95 %.
). Incluso si
tenemos muchos datos y estos provienen de una distribución normal (se
definirá este concepto más adelante), podremos llegar al 95 %.
- No es recomendable el uso de
ellas, cuando tampoco lo sea el de la media como medida de tendencia
central.
